
Overview
Climate change has become one of the most global challenges of our time. The emission of greenhouse gases, primarily attributed to human activities have caused an unprecednted rise in atmospheric carbon dioxide (CO2) levels, which is the primary cause of global warming. CO2 plays a crucial role in regulating the planet’s temperature. However, excessive amounts of CO2 can trap more heat from the sun, leading to an increase in the Earth’s temperature, which has significant implications for the environment, biodiversity, and human health. Therefore, understanding the impact of CO2 on climate change is essential to mitigate its effects and secure a sustainable future for generations to come.
Through this project I want to build a dashboard of CO2 to monitor and understand the change. The key questions are:
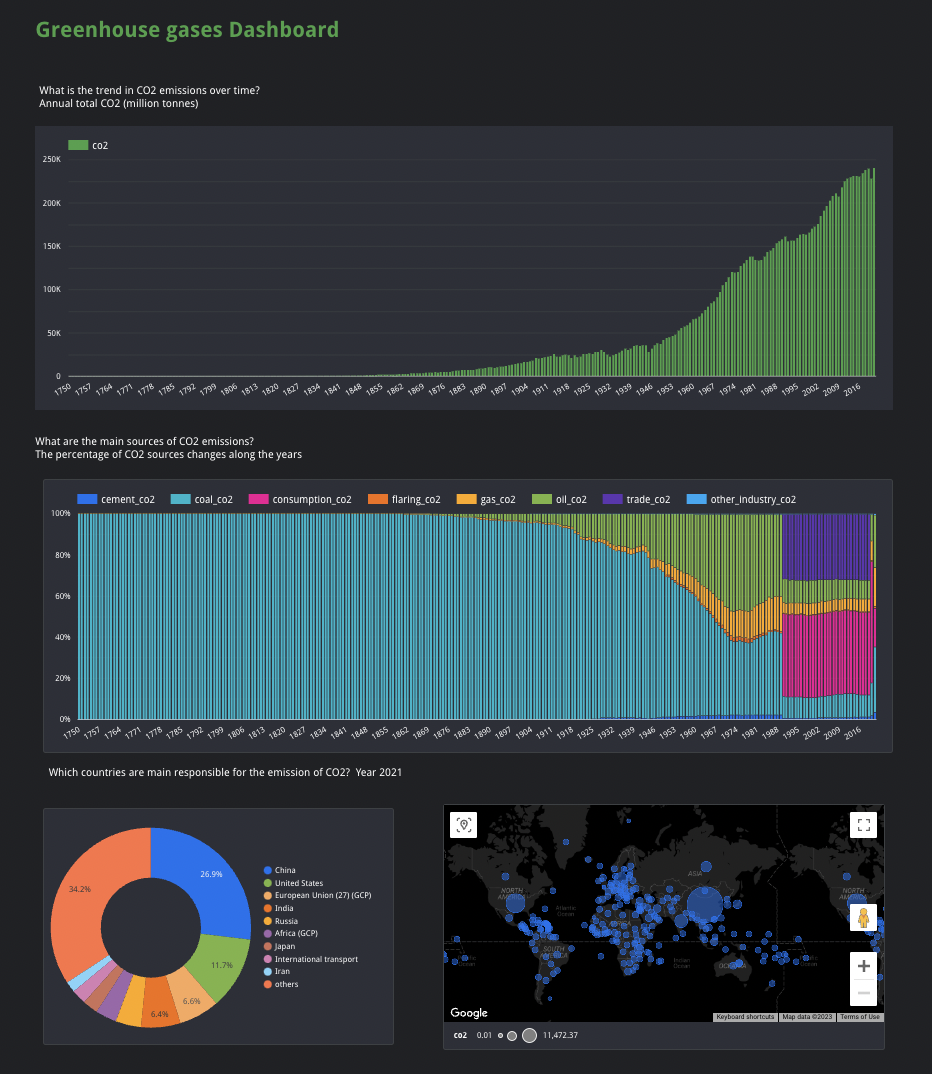
- What is the trend in CO2 emissions over time?
- What are the main sources of CO2 emissions?
- Which countries are main responsible for the emission of CO2?
The following diagram illustrates the architecture of the end-to-end data pipeline.
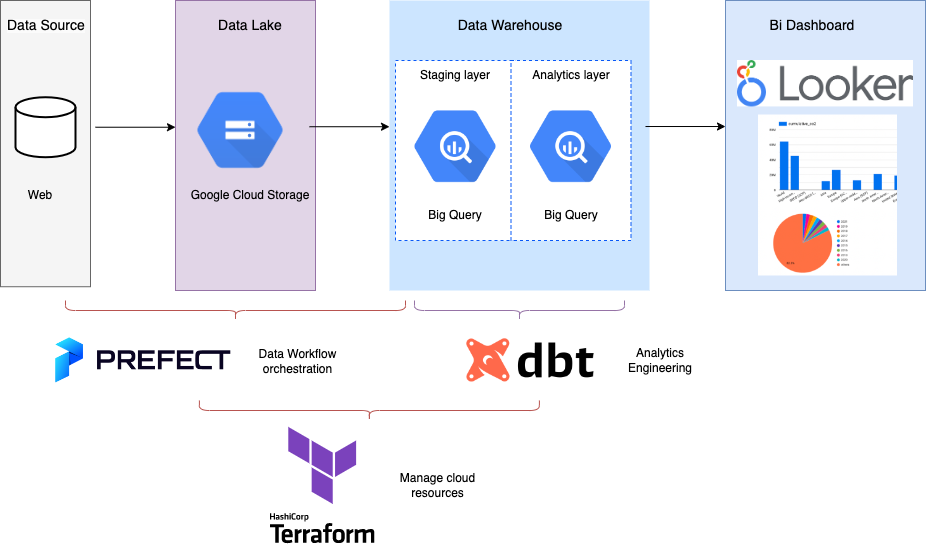
The Dataset
The dataset is credited to Our World in Data. The description of the dataset can be found in this codebook.
Technologies
- Cloud: GCP
- Infrastructure as code (IaC): Terraform
- Workflow orchestration: Prefect
- Data Warehouse: Big Query
- Batch Processing: Spark
Steps
Terraform to manage resources on GCP
-
Create a project on GCP. - Create a service account. Create and download a key in json (client-secrets.json). - Add permission for the service account principal to access GCP in IAM. Assign Storage Admin, Storage Object Admin, BigQuery Admin. - Enable IAM API in the https://console.cloud.google.com/apis/library/iam.googleapis.com
-
Install Terraform
- In the working directory, create a file called main.tf and paste the following Terraform configuration into it. Define variables in variables.tf.
terraform initTerraform has been successfully initialized!
terraform planPlan: 2 to add, 0 to change, 0 to destroy.
terraform applyApply complete! Resources: 2 added, 0 changed, 0 destroyed.
Prefect to orchestration data flows
- Upload data to GCS and BQ with Prefect
- Instll Prefect
- Check prefect version in terminal with
prefect version - Start Prefect Orion UI with
prefect orion start, Check out the dashboard at http://127.0.0.1:4200 - Create a new GCS Credential block and GCS bucket block.
- Run python code
Data Warehouse BigQuery
- Create external table
-- Create external table referring to gcs path CREATE OR REPLACE EXTERNAL TABLE `de-finalproject.co2_data.ext_co2` OPTIONS ( format = 'parquet', uris = ['gs://co2-data-bucket_de-finalproject/data/owid-co2-data.csv.parquet'] );
Analytics Engineering with dbt Cloud
- Create a new dbt project (connection to data warehouse, configuration the environment, create and link a repository to dbt project)
- Under Develop, initialize dbt project (a lot of templates and files are created). In version control, Commit and sync -> create branch -> git push to remote repo.
- Create models, select only necessary columns from data source.
dbt buildthe models and you will find the staging layer in BQ.
Dashboard with Looker Studio
- Import tables from BigQuery.
- Change the aggregation type of some columns.
- Build some charts with dimensions and metrics. Please click the report link hier: CO2 Report
Final words
What a learning journey! Thank you a lot for the free data engineering course provided by DataTalks.Club. The teaching teams and the communities are very helpful. In the past three months, I’ve experienced both struggles and satisfaction. I am extremely happy to complete this course and thrilled to apply the techniques and knowledge at my work. I am ready for the next challenge!
Reference:
- Data Engineering Zoomcamp in Github
- Cover photo from Gerd Altmann on Pixabay
- Final project Repo on GitHub
❤️ Please visit my home page for more contents. I look forward to connecting with you via LinkedIn.
❤️ You might like
